近年来人工智能的发展,已经从“大炼模型”逐步迈向了“炼大模型”的阶段。利用先进的算法,整合大规模的数据,汇聚大量算力,训练出巨量人工智能模型,是人工智能一直在探索的方向。9月28日,浪潮人工智能研究院发布全球最大规模人工智能巨量模型“源1.0”。作为中国自已的GPT-3,“源1.0”的单体模型参数量达2457亿,已超越美国OpenAI组织研发的GPT-3,成为全球最大规模的AI巨量模型。
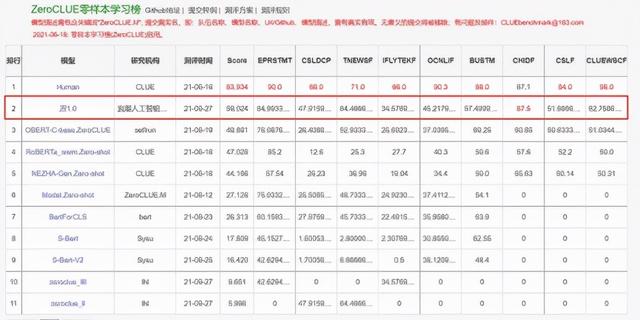
(ZeroCLUE零样本学习榜-第一行为人类得分)
据了解,“源1.0”在算法、数据、算力上,都做到了超大规模和巨量化。算法方面,相比于1750亿参数的英文语言模型GTP-3,“源1.0”共包含了2457亿个参数,是前者参数量的1.404倍。特别值得一提的是,“源1.0”和GPT-3一样都是单体模型,而不是由很多小模型堆砌起来的。
在谈及浪潮人工智能研究院为何会选择单体模型而不是混合模型时,浪潮人工智能研究院首席研究员吴韶华表示:“巨量模型领域,我们从模型能力的角度非常关注模型的零样本学习能力和小样本学习能力,这也是巨量模型最核心的能力,也是最吸引人的地方。我们选择单体模型跟这个特点是强相关,单体模型证明了它在这方面有特别出色的效果。”
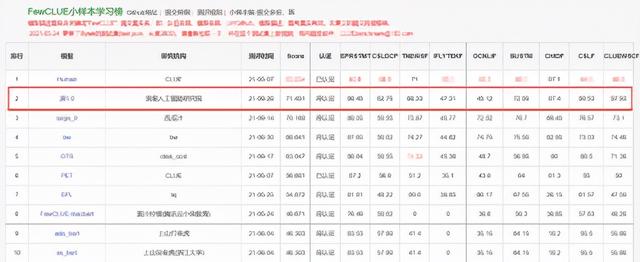
(FewCLUE小样本学习榜-第一行为人类得分)
事实上,巨量模型的发展备受关注。斯坦福大学李飞飞教授等人工智能领域知名学者近期在论文中表示,这类巨量模型的意义在于突现和均质。突现意味着通过巨大模型隐含的知识和推纳可带来让人振奋的科学创新灵感出现;均质表示巨量模型可以为诸多应用任务泛化支持提供统一强大的算法支撑。
“源1.0”模型参数规模为2457亿,相比GPT-3模型1750亿参数量和570GB训练数据集,源1.0参数规模领先40%,训练数据集规模领先近10倍;训练采用的中文数据集达5000GB,是迄今业界最大的高质量中文数据集。它总共阅读了大约 2000 亿词,是全球最大的中文数据集。源1.0中文巨量模型的发布,使得中国学术界和产业界可以使用一种通用巨量语言模型的方式,大幅降低针对不同应用场景的语言模型适配难度;同时提升在小样本学习和零样本学习场景的模型泛化应用能力。
浪潮表示,“源1.0”将面向学术研究单位和产业实践用户进行开源、开放、共享,降低巨量模型研究和应用的门槛,有效推进AI产业化和产业AI化的进步,让各个行业具备可感知、自学习、可进化的能力,最终帮助用户完成业务智能转型升级,以具备通用性的智能大模型成就行业AI大脑。
相关文章






关于作者

猜你喜欢































