在今天,狂热追捧ChatGPT,仿佛已经成为了一种“政治正确”。
ChatGPT一出,学界、工业界无不惊为天人。一位研究机构的资深研究员就对AI科技评论说过:“ChatGPT出来,直接给我们整不会了——生成做的比我们好就不说了,NLP(自然语言处理)能力还比我们强不少。”
微软注资百亿美元,谷歌则如临大敌,ChatGPT在科技圈里掀起的巨浪,仍是现在进行时。
但是,ChatGPT并非“万能钥匙”——大模型在某些专业领域的准确度,仍然无法超越其他垂类产品。近日,腾讯AI Lab 就通过实验证明,在机器翻译领域,ChatGPT在某些情况下,能力弱于其他商业翻译产品。

图1: ChatGPT推荐的10个可引发其进行机器翻译的prompt
生成的提示语看起来很合理,但是都有相似的格式,研究人员将它们总结成三个候选prompt(如图2),其中[SRC] 和 [TGT] 分别代表翻译的源语言和目标语言。另外,研究人员在Tp2中增加了一个额外命令,要求ChatGPT不要在翻译的句子上加双引号(在原始格式中经常发生)。尽管如此,ChatGPT依旧不稳定,如会将同一批次的多行句子翻译成单行。

图4:ChatGPT在多语言翻译中的表现
研究者认为,英语和罗马尼亚语之间的单一语言数据的巨大资源差异,限制了罗马尼亚语的语言建模能力,这部分解释了将英语翻译成罗马尼亚语表现差的原因。
相反,罗马尼亚语译成英语可以受益于强大的英语建模能力,使平行数据的资源缺口可以得到一定程度的补偿。
语系
同时,研究人员也考虑了语系的影响。
通常认为,对于机器翻译,不同语系之间的翻译通常比同一语系间翻译更难。研究人员发现,德英互译、汉英互译,或者德汉互译在文化和书写方式上存在差异。
另外可以发现,在这几种翻译中,ChatGPT和几款商业翻译软件间差距较大,研究者认为,这是因为在同一语系中知识转移比在不同语系间要好,对于既是低资源又来自不同语系的语言来说(如罗马尼亚语和汉语的互译),这种差距会进一步扩大。
由于ChatGPT在一个模型中处理不同的任务,低资源的翻译任务不仅与高资源的翻译任务竞争,而且还与其他NLP任务竞争模型容量,这说明其性能表现欠佳。
翻译鲁棒性
腾讯AI Lab进一步评估了ChatGPT在WMT19 Bio和WMT20Rob2和Rob3测试集上的翻译鲁棒性,这些测试集引入了领域偏见和潜在的噪声数据。
例如WMT19 Bio测试集是由Medline摘要组成的,这需要特定领域的知识处理,WMT20Rob2是来自Reddit的评论,可能包含各种错误,如拼写错误、单词遗漏、插入重复、语法错误、破坏性语言,和网络俚语等。图5列出了BLEU分数,显然ChatGPT在WMT19 Bio和WMT20Rob2测试集上的表现不如谷歌翻译和DeepL Translate。
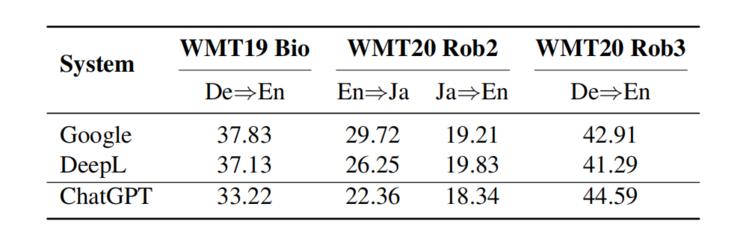
图5:ChatGPT在翻译鲁棒性方面的表现
原因可能在于,像谷歌翻译这样的商业翻译产品往往需要不断提高其翻译特定领域(如生物医学)或噪音句子的能力,因为它们是现实世界的应用,需要对分布之外的数据有更好地概括性,ChatGPT不太能够完成这一点。
不过,一个有趣的发现是,ChatGPT在包含众包语音识别语料的WMT20Rob3测试集上大大超过了谷歌翻译和DeepL Translate。这表明,ChatGPT本质上是一个人工智能对话工具,能够比商业翻译软件生成更自然的口语(见图6)。

图6:来自WMT20鲁棒集set3的例子
2ChatGPT应如何扬长避短?
从该研究可知,高举高打的ChatGPT每训练一次就耗费大量算力资源,但也不能在全领域尽善尽美。所以,一些人开始思考,是否应该“摒弃”大模型思路,转而去做“精耕细作”的小模型。
腾讯AI Lab在Chat GPT“测评”中提到,罗马尼亚语与英语互译,相较德英互译存在较大差距,原因在于:巨大资源差异,限制了罗马尼亚语的语言建模能力,也恰恰证明,AI学习能力常常受到低资源的掣肘。
但也有资深学者认为,尽管现时ChatGPT仍存在不少不足之处,但仍然对研究者和创业者有着不少启示。以ChatGPT为代表的AI 3.0走的是跟过去 AI 浪潮不一样的路,即更落地、更接近真实世界,在工业应用上,更直接,更落地,从学术研究到工业落地的路径也变得更短、更快。
未来,“helpful, truthful, harmless”的 AI 系统会成为现实。
雷峰网雷峰网
相关文章









关于作者

猜你喜欢
成员 网址收录40406 企业收录2984 印章生成243200 电子证书1087 电子名片62 自媒体71458































