杨净 发自 凹非寺量子位 报道 | 公众号 QbitAI
今天,谷歌大脑声称,他们新技术能训练万亿级参数的语言模型。

与此同时,此次也首次展现了大型稀疏模型(参数量惊人,但计算成本恒定)也可以用较低精度的格式进行训练。
迄今最大语言模型Switch Transformer的设计原则是,用一种简单有效的稀疏性扩展Transformer模型的参数量。
它建立在专家混合的基础上,这是90年代初首次提出的人工智能模型范式。
简单来说,就是在一个更大的模型内保留多个专家,或专门从事不同任务的模型,并由一个“门控网络”为任何给定数据选择咨询哪些专家。
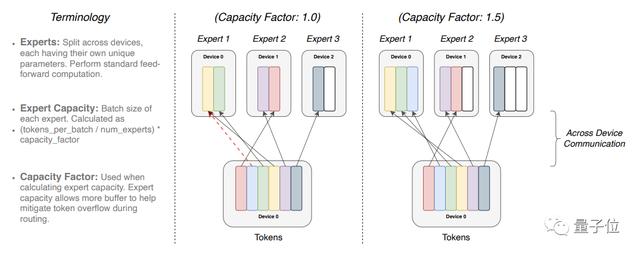
接着,研究人员使用了32个TPU内核在一个数据集上预训练了几个不同的Switch Transformer模型。
这一数据集叫做Colossal Clean Crawled Corpus,750GB大小,包含了从Reddit、维基百科和其他网络资源中搜索的文本。
研究人员给这些模型布置了任务,比如,在有15%单词被掩盖的段落中预测出缺失的单词;检索文本来回答问题。
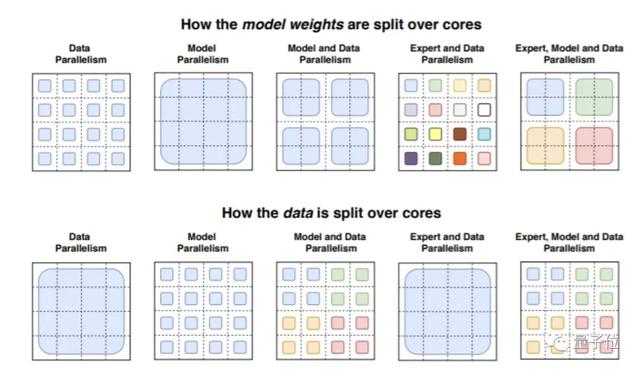
研究人员表示,他们拥有2048个专家系统的1.6万亿参数模型(Switch-C)“完全没有不稳定性”,其速度相比于T5-XXL模型提升了4倍。
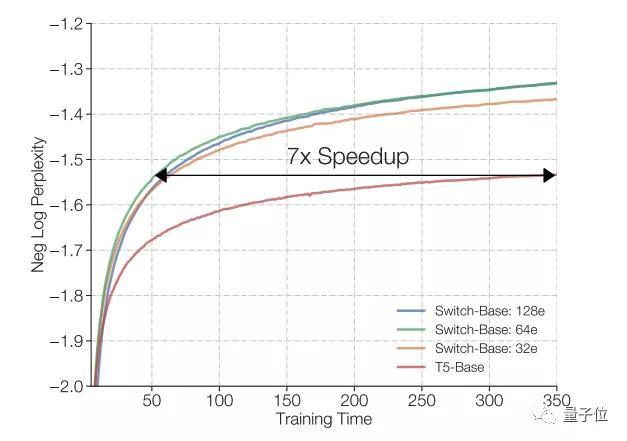
此外,研究者还将模型与T5-Base和 T5-Large进行了对比,结果表明,在相同的计算资源下,新模型预训练速度有最高7倍的提升。
研究人员表示,大型稀疏模型可用于创建较小的密集模型,在任务上进行微调,其质量增益为大型模型的30%。

从整体结果上看,Switch Transformer 模型在多项推理和知识任务中带来了显著性能提升。这说明该模型架构不只对预训练有用,还可以通过微调将质量改进迁移至下游任务中。
研究人员表示,
我们无法完全保留模型质量,但通过将我们的稀疏模型提炼成密集模型,可以实现10到100倍的压缩率,同时实现约30%的专家模型的质量增益。
在未来的工作中,研究人员计划将Switch Transformer应用于不同模态或多模态模型,包括图像和文本。
参考链接:论文地址:https://arxiv.org/abs/2101.03961https://venturebeat.com/2021/01/12/google-trained-a-trillion-parameter-ai-language-model/
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
相关文章








关于作者

猜你喜欢
成员 网址收录40407 企业收录2984 印章生成245562 电子证书1091 电子名片63 自媒体77176































