Pengfei Liu 投稿自 凹非寺
量子位 | 公众号 QbitAI
评估大模型对齐表现最高效的方式是?
在生成式AI趋势里,让大模型回答和人类价值(意图)一致非常重要,也就是业内常说的对齐(Alignment)。
“让大模型自己上。”
这是上海交通大学生成式人工智能研究组(GAIR)提出的最新思路。
但是目前的评估方法还存在透明度不够、准确性不佳等问题。
所以研究人员开源了一个130亿参数规模的大模型Auto-J,能对评估当下大模型的对齐效果。
它可同时分析两个大模型的回答,分别做出评价并进行对比。
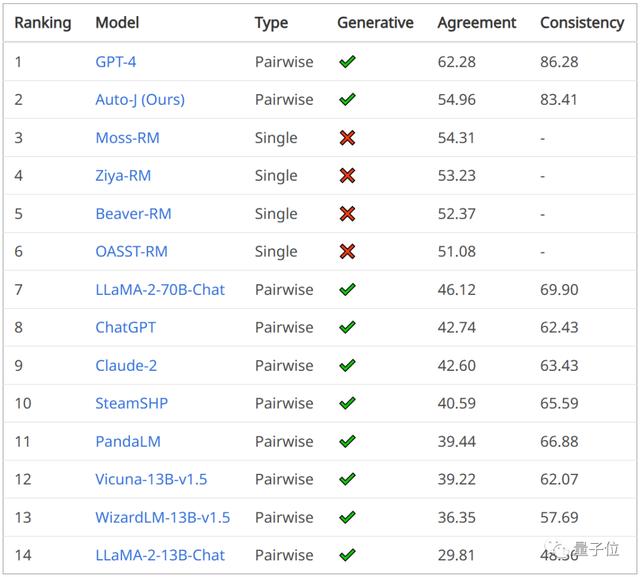
也能评估单个回复。并且在这一任务上的表现超越了GPT-4。

Auto-J给出的判断是Claude-1的回复更好,原因是信息更丰富、吸引人、个性化。
同时它也给出了具体的分析过程,从目的、语气、正文内容、个性化、信息丰富度几个方面评估,并讲明了各个方面两个大模型的优劣。
 支持50 场景
支持50 场景在性能表现上,Auto-J在以下两方面都表现不错。
功能使用方面支持50 种不同的真实场景的用户问询(query)(如常见的广告创作,起草邮件,作文润色,代码生成等)能够评估各类大模型在广泛场景下的对齐表现;
它能够无缝切换两种最常见的评估范式——成对回复比较和单回复评估;并且可以“一器多用”,既可以做对齐评估也可以做“奖励函数”(Reward Model)对模型性能进一步优化;
同时,它也能够输出详细,结构化且易读的自然语言评论来支持其评估结果,使其更具可解释性与可靠性,并且便于开发者参与评估过程,迅速发现价值对齐过程中存在的问题
性能开销方面在性能和效率上,Auto-J 的评估效果仅次于GPT-4而显著优于包括ChatGPT在内的众多开源或闭源模型,并且在高效的vllm推理框架下能每分钟评估超过100个样本。
在开销上,由于其仅包含130亿参数,Auto-J能直接在32G的V100上进行推理,而经过量化压缩更是将能在如3090这样的消费级显卡上部署使用,从而极大降低了LLM的评估成本 (目前主流的解决方法是利用闭源大模型(如GPT-4)进行评估,但这种通过调用API的评估方式则需要消耗大量的时间和金钱成本。)
具体方法训练数据总体上遵循如下的流程示意图:
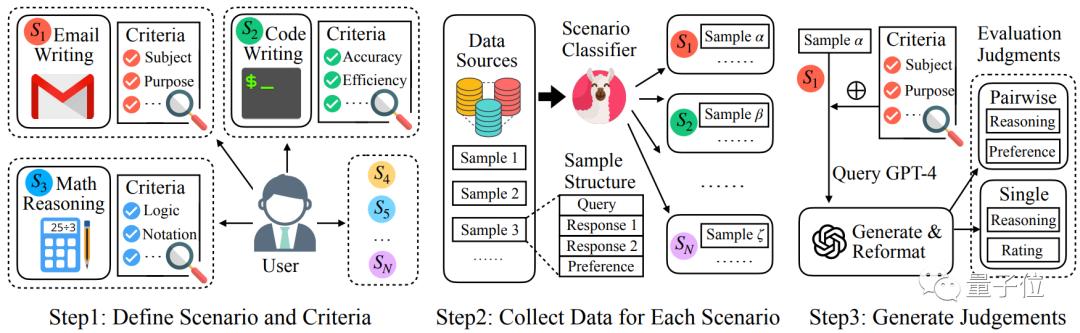
△不同模型作为奖励模型的表现
最后,开发者也探究了Auto-J在系统级别的评估表现。
对AlpacaEval(一个流行的基于GPT-4评估的大模型排行榜)上提交的开源模型使用Auto-J的单样本打分进行了重新排序。
可以看到,基于Auto-J的排序结果与GPT-4的排序结果有极高的相关性。
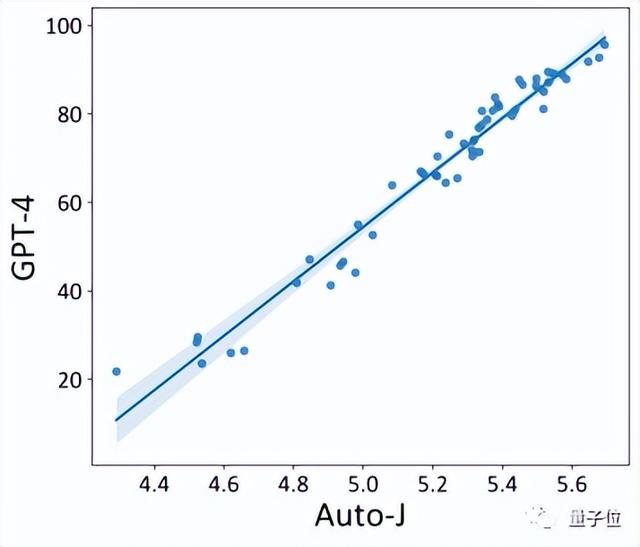
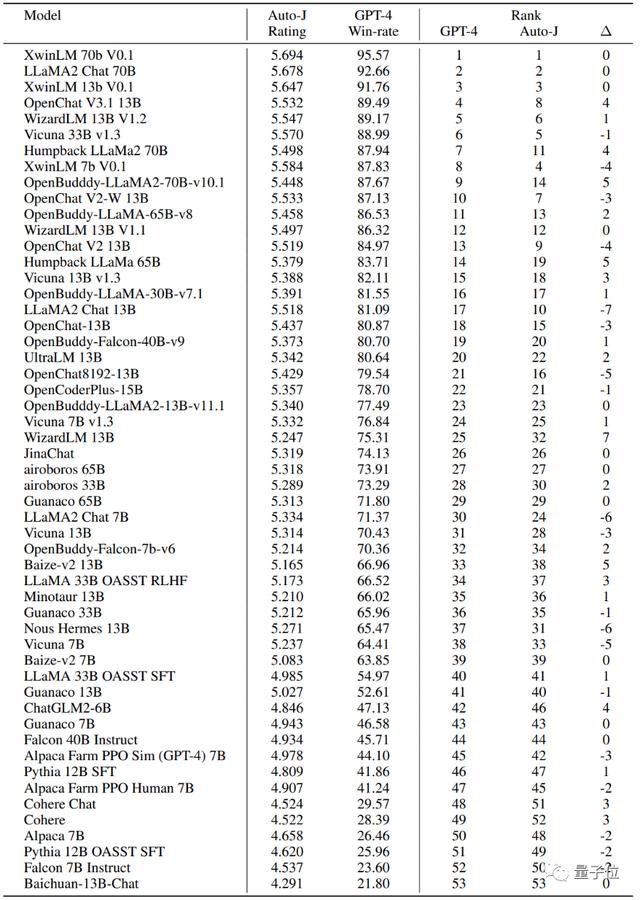
△Auto-J与GPT-4对AlpacaEval排行榜提交的开源模型排序之间的相关性及具体排名数据
作者总结和展望总结来说,GAIR研究组开发了一个具有 130 亿参数的生成式评价模型 Auto-J,用于评估各类模型在解决不同场景用户问询下的表现,并旨在解决在普适性、灵活性和可解释性方面的挑战。
实验证明其性能显著优于诸多开源与闭源模型。
此外,也公开了模型之外的其他资源,如模型的训练和多个测试基准中所使用的数据,在构建数据过程中得到的场景定义文件和参考评估标准,以及用以识别各类用户问询所属场景的分类器。
该项目具体的论文、主页信息如下:
论文地址:https://arxiv.org/abs/2310.05470项目地址:https://gair-nlp.github.io/auto-j/代码地址:https://github.com/GAIR-NLP/auto-j
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
相关文章









关于作者

猜你喜欢
成员 网址收录40406 企业收录2984 印章生成243655 电子证书1088 电子名片62 自媒体71531































